내가 경험한 DDD, Hexagonal share
최근에 플렉스 로 이직을 했다. 부릉(舊 메쉬코리아) 에서 7년간 배우고 적용했던 DDD Domain Driven Design, 도메인 주도 설계와 Hexagonal Architecture Pattern육각형 구조에 대해 한판 정리하면서, 지난 시간을 회고해 본다.
2016년 마흔이 넘은 나이에 하던 일을 그만 두고 직업 개발자로 전업을 위한 준비를 하던 시절이었다. 한 통의 전화를 받고 티타임을 하러 갔다가, 우선 시간을 벌며 다음 기회를 보자는 심산으로 입사하기로 약속했다.
입사하기 전까지는 전혀 몰랐다. 공동설립자 대부분이 과학고 등 특수고를 나와서 미국에서 대학을 졸업했고, 국제 정보 올림피아드에서 우승한 이력도 있는 천재 개발자 집단이었다(당시 대표는 개발자 아님). 국내 대학을 나오지 않았기에 고등학교 동료나 동료들의 친구들로 초기 팀업을 했다. 팀 또한 어마어마했다. 그런데 첫 서비스를 실패했다. 내가 합류했던 시점은 새 서비스로 피봇팅하던 때였다. 그 서비스가 지금의 사명과도 같은 부릉이다.
나는 운이 참 좋은 사람이다. 합류할 때부터 DDD를 시전하며 Agile 방식으로 일하고 있었고, 부릉 서비스도 당연히 DDD 사상이 들어갔다. 직업 개발자로 전업을 하기 위한 전략으로 개발 서적을 한권 집필 했기에 해당 웹 프레임워크를 자유롭게 다룰 수 있고 어찌저찌 원하는 서비스를 만들 수 있는 수준이었지만, 괜찮은 팀에서 괜찮은 동료들로부터 소프트웨어 설계를 배운 경험은 전무했다.
급하게 DDD를 배울 수 있는 책을 찾았고, 처음 접한 책이 범균님의 DDD START! (현재는 절판되고 신버전 출시됨) 라는 책이었다. 그동안 내가 만든 소프트웨어가 얼마나 엉망이었는지 심각하게 각성하는 계기가 됐다. 이어서 Evans와 Vernon의 책도 섭렵했다. 그 때부터 지하철로 출퇴근하며 소프트웨어 고전들을 하나씩 읽어나갔고, 배운 내용은 실무에 차근차근 적용해 나갔다.
입사부터 2년 동안은 PHP/Laravel로 Legacy 서비스를 개발하고 운영했다. Laravel은 Active Record 패턴으로 구현한 ORM을 사용하고 있어서 DDD를 적용하는데 고전했던 기억이 난다. 그 뒤엔 Java/Spring으로 MSA 서비스들을 개발하고 운영했다. MSA로 전환할 때 DDD의 Bounded Context 개념이 큰 도움이 되었다. 최근 몇 년 동안은 Layered 대신 Hexagonal로 애플리케이션을 구성했고, 외부 세상과 애플리케이션을 분리함으로써 얻는 잇점들도 경험했다.
공동 설립자들도 활발하게 실무 개발에 참여했다. 회사의 직원이 200명이던 시절, CTO 타이틀을 달고도 실무 개발하는 장면을 목격하고, “더 중요한 일을 하셔야 할 분이 개발 좀 그만하시라” 고 말했던 적이 있다. 입사하기 전에 잘난 척했지만, 결국 우물안 개구리였다는 사실을 깨닫는데 오래 걸리지 않았다. 이 분들은 실무 개발 지식 뿐만아니라, 문제 해결 능력도 뛰어나고, 부릉 서비스 초기에 거의 매일 자정까지 야근하는 나보다 더 열심히 일했다.
가장 많이 타 본 차의 운전 스타일을 닮는다고 한다. 난 아버지 차를 가장 많이 타 봤고, 아버지의 운전 스타일을 그대로 닮았다. 내가 개발자로 일하는 방식, 구현 스타일은 부릉의 공동 설립자 및 동료 개발자들의 영향을 많이 받았다. 이 포스트를 통해 감사의 마음을 한번 더 표현한다.
입사 당시 100명 남짓이었고, 퇴사할 때 공동 설립자를 제외하고 나보다 사번이 높은 직원은 두세 명에 불과했다. 부릉 서비스 시작 시점에 하루 천 개도 안되는 배송 신청을 받았다면, 퇴사할 땐 하루 30만개의 배송을 소화했다. 배송 기사, 상점, 관리자의 트래픽을 받는 Public API는 분당 15만 요청을 처리하는 수준이었다. 연 4천억원 매출, 매출원가 90%를 제하면 10%가 마진, 백엔드 15명, 웹 3명, 안드로이드 3명, 닷넷 2명, QA 2명, PO 3명, 디자인 2명, 회사는 hy(한국야쿠르트)에 인수 등이 퇴사 시점의 스냅샷이다 - 현재는 조직, 사업, 서비스가 매우 안정적이란 얘기를 하고 싶었다. 더군다나 2022년 미국발 금융 위기로 바닥을 찍어 봤기에 이제 올라갈 일만 남았다.
운 좋게 J-curve를 그리며 트래픽을 쳐맞는 성장을 경험했지만, 월급 외에 주식 보상에서는 오히려 운이 없었다. 배움과 성장의 비용이라 생각하고 잊어버렸다.
이 포스트는 필자가 이해하는 Hexagonal과 DDD를 간략히 설명하는 것이 목적입니다. 이 포스트에 사용한 예제 코드는 https://github.com/appkr/hexagonal-example 에서 볼 수 있습니다. 이 포스트의 내용을 정답이 아닙니다, 다시 한번 강조드리지만 세상에 정답은 없습니다.
Hexagonal
Hexagonal의 핵심을 토비님이 설명해주셨습니다.
헥사고날의 핵심은 가운데 헥사곤 안에 들어있는 애플리케이션과 외부 세상을 분리하는게 출발입니다. 헥사고날을 만든 Cockburn은 시스템을 사용하는 사용자와 시스템이 사용하는 네트워크, DB를 외부에 있는 것이라고 보고 이를 어댑터라고 모아 불렀습니다. 🔗
주) 애플리케이션을 사용하는 driving adapter와 애플리케이션이 사용하는 driven adapter
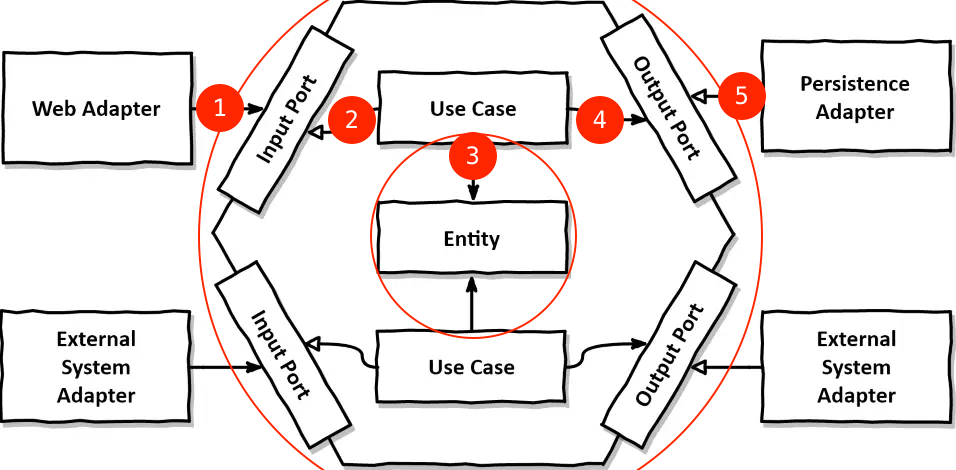
UML의 기초는 has-a와 is-a입니다. has-a는 ->로 표시합니다 이 문맥에서는 “사용한다” 라고 읽어도 좋습니다. is-a는 속이 빈 화살표, -|>로 표시합니다 “구현한다” 라고 읽습니다. 이것만 알아도 대부분의 UML을 읽을 수 있습니다. 그림은 이렇게 읽을 수 있습니다.
- ①
WebAdapter는InputPort를 사용합니다 - ②
Usecase는InputPort를 구현합니다 - ③
Usecase는Entity를 사용합니다 - ④
Usecase는OutputPort를 사용합니다 - ⑤
PersistenceAdapter는OutputPort를 구현합니다
이상의 기본 이해를 바탕으로 다음과 같은 폴더 구조를 도출했습니다. 이 구조는 정답은 아니고, 일례일 뿐입니다.
아래 폴더 구조 및 네이밍은 그림과는 조금 다릅니다.
InputPort를ProductUsecase라 불렀습니다- 그림의
Usecase를ProductService라 불렀습니다 PersistenceAdapter는 구현 기술 명칭을 포함한ProductJpaRepository로 이름 지었습니다- 그림에서 큰 바깥쪽 원을
application이란 패키지로, 안쪽의 작은 원을domain패키지로 명명했습니다.
├── HexagonalExampleApplication
├── adapter
│ ├── inbound
│ │ └── rest
│ │ └── ProductController
│ └── outbound
│ ├── kafka
│ │ └── ProductMessageProducer
│ └── jpa
│ └── ProductJpaRepository
└── application
├── domain
│ └── Product
├── port
│ ├── inbound
│ │ └── ProductUsecase
│ └── outbound
│ ├── MessagePort
│ └── ProductRepository
└── ProductService
서브 도메인이 여러 개인 모노리식 애플리케이션을 개발한다면 이런 구조로도 확장할 수 있을 겁니다.
├── bootstrap
│ ├── CommerceApplication
│ └── config
├── order
│ ├── adapter
│ └── application
├── product
│ ├── adapter
│ └── application
├── delivery
│ ├── adapter
│ └── application
└── payment
├── adapter
└── application
실무 사례
폴더 구조만 보고 머릿 속에 그림이 잘 안그려질 수 있을 것 같아, 실무 사례를 가져왔습니다.
왼쪽의 폴더 구조만 보고도 뭘하는 애플리케이션인지 알아차렸을겁니다. 총 네 가지의 유스케이스를 제공하는 서비스입니다.
- (1) 지오코드:
(주소) -> 좌표 - (2) 역지오코드:
(좌표) -> 주소 - (3) 주소 검색:
(검색어) -> 주소[] - (4) 주소 정제:
(더러운 주소) -> 깨끗한 주소
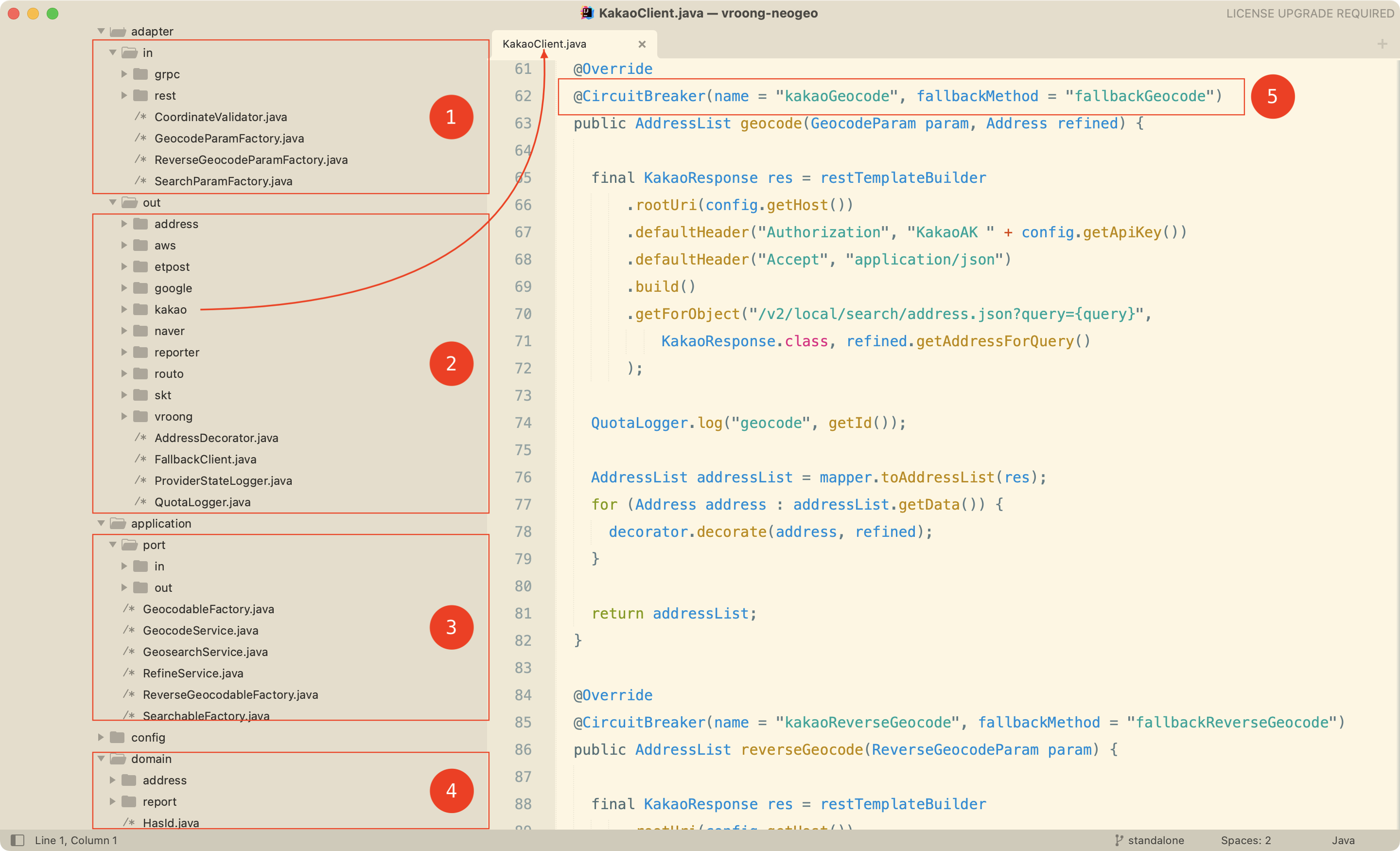
- ④ 이 프로젝트에서는
domain을application과 같은 폴더 레벨로 위치시켰습니다 - ③
port.in은 외부 세계의 요청을 받고,port.out은 외부 세계에 요청을 하기 위한 인터페이스입니다 - ①
adapter.in.rest에는@RestController가 있어서 HTTP 프로토콜로 클라이언트의 요청을 받아서port.in에 위치한Usecase를 구동driving합니다;adapter.in.grpc에는 gRPC 서비스 구현체가 있어서 gRPC 프로토콜로 클라이언트의 요청을 받아서Usecase를 구동합니다 - ②
Usecase의 구현체인~Service가port.out의 여러 인터페이스를 사용하고,port.out의 구현체는adapter.out에 위치합니다. 여기서 의존성 역전이 발생합니다.- 파일 저장을 위해
awsS3 저장 기능을 구현했습니다 - 주소 정제를 위해
etpost엔진과 TCP 통신을 합니다 - 영문 주소 번역을 위해
google번역 서비스를 이용합니다 - (역)지오코드 및 검색을 위해
kakao,naver,skt,routo등과 통신하는 구현했습니다 - 주소 정제 실패 로그를 쌓고 슬랙 메시지를 보내는 리포팅 기능은
reporter에 구현했습니다 - 벌크 요청에 대해 비동기로 처리하고 처리 결과를 사용자에게 알리기 위해 이메일을 선택했고
vroong에 부릉의 공통 메일 전송 MSA와 통신하는 기능을 구현했습니다.
- 파일 저장을 위해
- ⑤ 우리 마음대로 제어할 수 없는 외부 서비스의 장애가 내부로 전파되는 것을 막기 위해 회로 차단기 패턴을 적용한 모습을 보여줍니다. 아울러, 외부 서비스로부터 받은 응답은 모두 부패방지계층 ACL, Anti-corruption Layer을 적용하고 갑작스런 API 변경으로부터 우리 서비스를 보호하도록 완충 역할을 제공했습니다
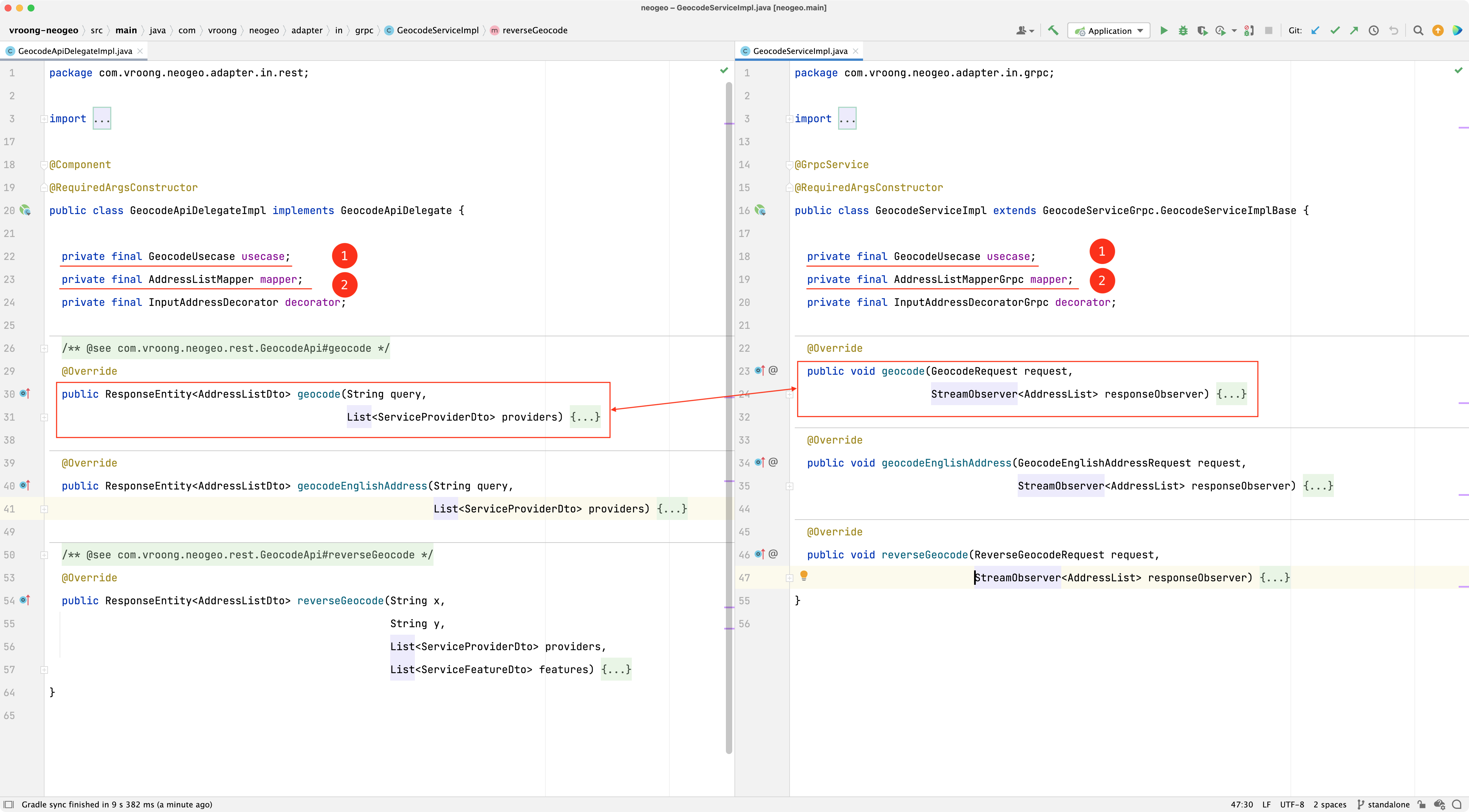
위 그림의 왼쪽은 rest, 오른쪽은 grpc로 똑같은 지오코드 유스케이스를 호출하는 컨트롤러입니다.
- ① 둘이 똑같은
Usecase를 주입받아 사용합니다.rest와grpc를 통해 제출받은 데이터 형식은 서로 다를 수 있습니다. 그것을 컨트롤러에서Usecase가 받을 수 있는 형식으로 치환합니다. - ② 마찬가지로 응답 형식이 서로 다를 수 있습니다.
Usecase로부터 받은 모델을 각 딜리버리 메커니즘에 맞도록~Mapper가 맵핑합니다. 맵핑 로직은 기술 종속적이기때문에adapter에서 처리하는 것이 적절하다고 판단했습니다.
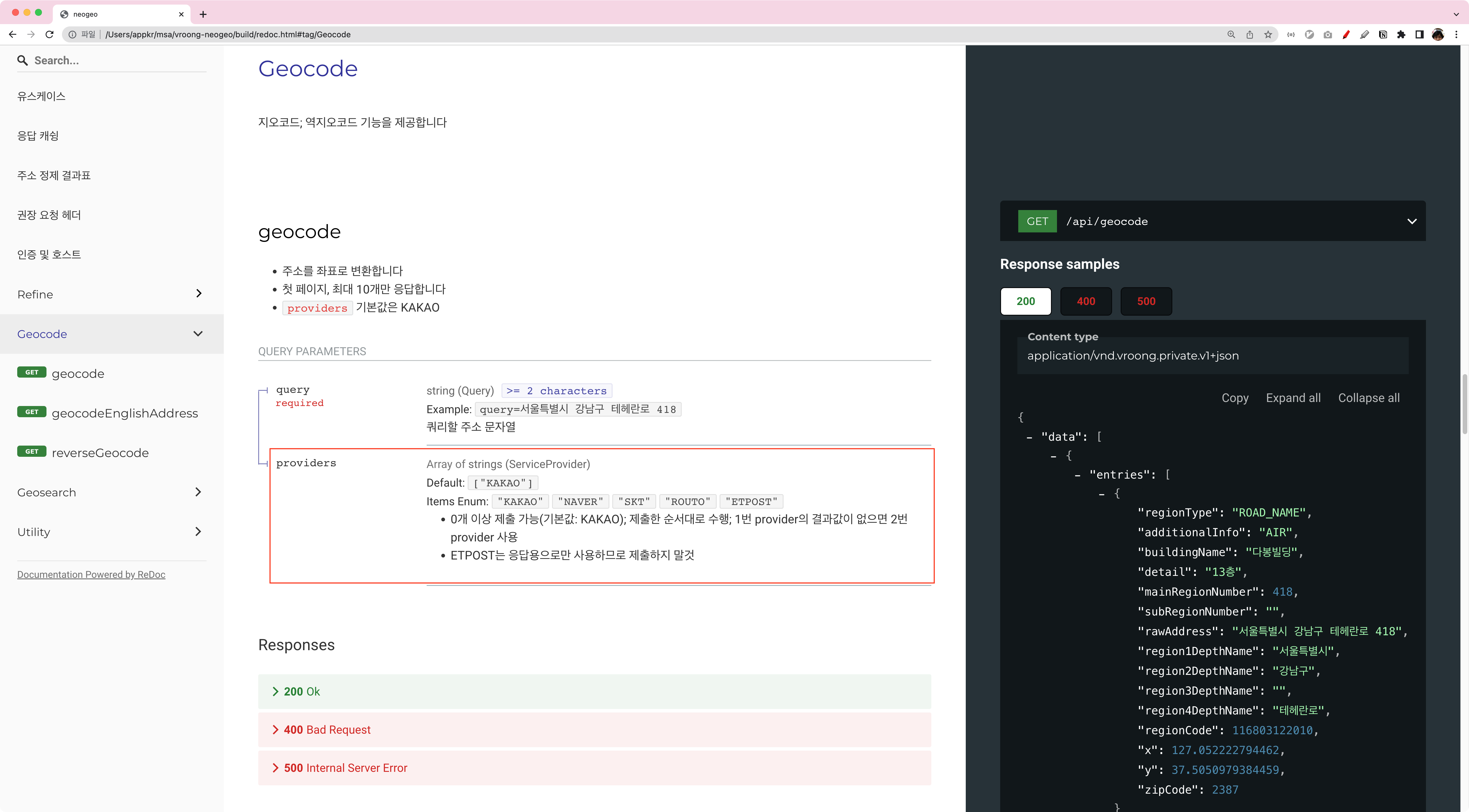
이상의 복잡성은 모두 감추어져 있습니다. 클라이언트가 마주하는 API는 그림과 같은 모양입니다. providers 쿼리 파람을 잘 보면, 배열로 제출합니다. 가령 providers=KAKAO,NAVER,SKT와 같이 제출했다면, 카카오 지오코드가 실패하면(결과 값이 없거나, 장애로 인해 오류 응답을 받으면), 네이버로 폴백합니다. 네이버도 실패하면, SKT로 넘어갑니다. 각 서비스에서 지오코드라는 유스케이스를 위해 카카오, 네이버 등을 직접 연동하고 호출하던 것을 이 서비스가 추상화해서 공통 서비스로 제공하고 있습니다. 적용 우선 순위 또는 객체의 조립 공식을 클라이언트가 선택할 수 있도록 유연함도 제공하고 있을 뿐더러, 외부 서비스의 충격으로부터 우리 서비스를 보호하고 있습니다.
이상한 용례이긴하지만, 서버에 CLI로 접속해서 이 애플리케이션을 이용해 지오코드를 결과를 얻을 수 있을까요? 물론이죠, adapter.in.cli를 구현하고, Usecase를 그대로 사용하면 됩니다. 스케쥴 태스크, 카프카 컨수머 등등이 adapter.in에 위치하면 됩니다. 새로운 지오 서비스 프로바이더를 추가할 수 있을까요? adapter.out.newgeoprovider를 port.out의 스펙대로 구현하고 객체를 조립하는 Factory 클래스의 switch 구문에 추가해주면 됩니다.
필자는 실용 주의자입니다, 해서
Usecase를 사용하는 클래스의 테스트 불편함만 없다면 가끔Usecase인터페이스를 생략하고~Service구체 구현체만 작성하기도 합니다
DDD
DDD의 핵심은 소프트웨어의 복잡성 제어입니다. Evans의 책 제목에 정확히 그렇게 써 있습니다.
Domain-Driven Design: Tackling Complexity in the Heart of Software
애플리케이션은 시간이 지나면서 필연적으로 복잡하지기 마련입니다. 복잡도가 올라가면 개발자의 뇌부하가 높아지고, 버그에 노출되기 쉬우며, 유지보수 비용이 증가하게 됩니다. 이런 문제점을 해결하는 방법 중의 하나가 DDD입니다. 범균님의 소프트웨어의 복잡성에 관한 인프런 객체지향 강의 섹션1(무료) 시청을 강력히 권장합니다.
애플리케이션의 복잡성 정복에 DDD가 어떤 도움을 주는 지 필자 나름의 의식의 흐름대로 풀어 보겠습니다.
과거에 clang, perl, classic PHP, classic ASP, JSP로 웹 애플리케이션을 만들던 시절이 있었습니다 필자가 90년 말에 가지고 놀던 perl 코드 clang으로 짠 웹. 고작 일천줄 수준인데 전혀 읽히지 않습니다. 일만줄 코드는 천재들이나 작성할 수 있다고 생각했습니다, 왜냐하면 일만줄의 작업 컨텍스트를 머릿속에 넣고 있어야 하니까요. 객체지향을 배우고 신세계를 경험했습니다. 클래스 내부의 데이터와 메서드, 협력하는 몇 개의 협력 클래스만 기억하면 천재 개발자가 아니어도 제법 큰 프로그램도 짤 수 있었으니까요. 게다가 RubyOnRails, Laravel과 같은 MVC 패턴을 접하고는 생산성은 더 올라갔습니다.
클래스(메모리에 올라가면 “객체”, 이하 두 용어를 혼용해서 사용함)란 데이터와 그 데이터를 조작하는 함수를 캡슐화해 놓은 겁니다.
그런데, 잘 생각해보자구요. 우리가 애플리케이션을 작성하면서 만나는 데이터, 즉 상태를 가진 클래스가 어떤 것이 있었죠? 컨트롤러, 서비스, 리포지토리 전부 상태가 없습니다. 상태가 없으니 서비스 컨테이너에 싱글톤으로 등록하고 필요할 때 꺼내써도 멀티 스레드 환경에서도 동시성 이슈가 생기지 않는겁니다. 이 녀석들이 멤버 필드로 다른 클래스를 가지고 있지만, 그 클래스들은 협력 클래스일 뿐이고, 앞서 언급한 싱글톤 클래스들은 메서드로 받은 원시타입 또는 DTO를 다른 협력 클래스의 메서드에 전달하는 역할만 하잖아요. 그렇게 따지고 보면 DTO를 제외하고 데이터, 즉 상태를 가진 클래스는 도메인 객체가 전부입니다.
(백엔드) 애플리케이션이란 결국 비즈니스 객체의 상태를 관리하는 것이고, 그 상태를 제어하는 창구를 한 곳으로 모아 두면 상태가 잘못 되는 일은 없지 않을까요? DDD에는 보편언어 Ubiquitous Language, 바운디드 컨텍스트, 컨텍스트 맵과 같은 전략적 패턴을 주장하고 있지만, 실천적인 전술적 패턴을 많이 제공하고 있습니다.
그 실천적 패턴들은 결국 도메인의 상태를 잘 관리하기 위한 것이고, 애그리거트 루트 Aggregate Root에만 그 진입점을 만들라고 가이드합니다. 그리고 도메인에 대한 지식을 여기 저기 흩어 놓지 말고, 도메인 모델 안에 집약하라고 제언합니다. (모델이 뭐냐고 질문하시는 분이 있어서) DDD에서는 모델을 식별자가 있어 식별자로 객체간 동일성을 식별하는 1) 엔티티, 객체의 값으로 서로간의 동일성을 식별하는 2) 밸류로 구분합니다.
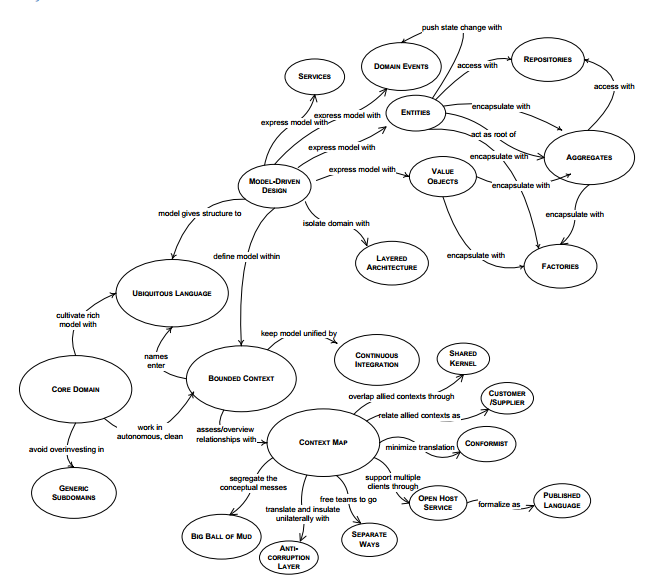
그림에서 보듯이 꽤 많은 실천 패턴들을 제안하고 있는데, 제가 그럴 깜냥이 안되거니와, 이 포스트에서 전부 설명할 수는 없습니다. 책을 사서 보실 것을 추천합니다. 지금 당장 전부 볼 수는 없으니, 실무 사례를 통해 이해도를 높여 보려 합니다.
실무 사례
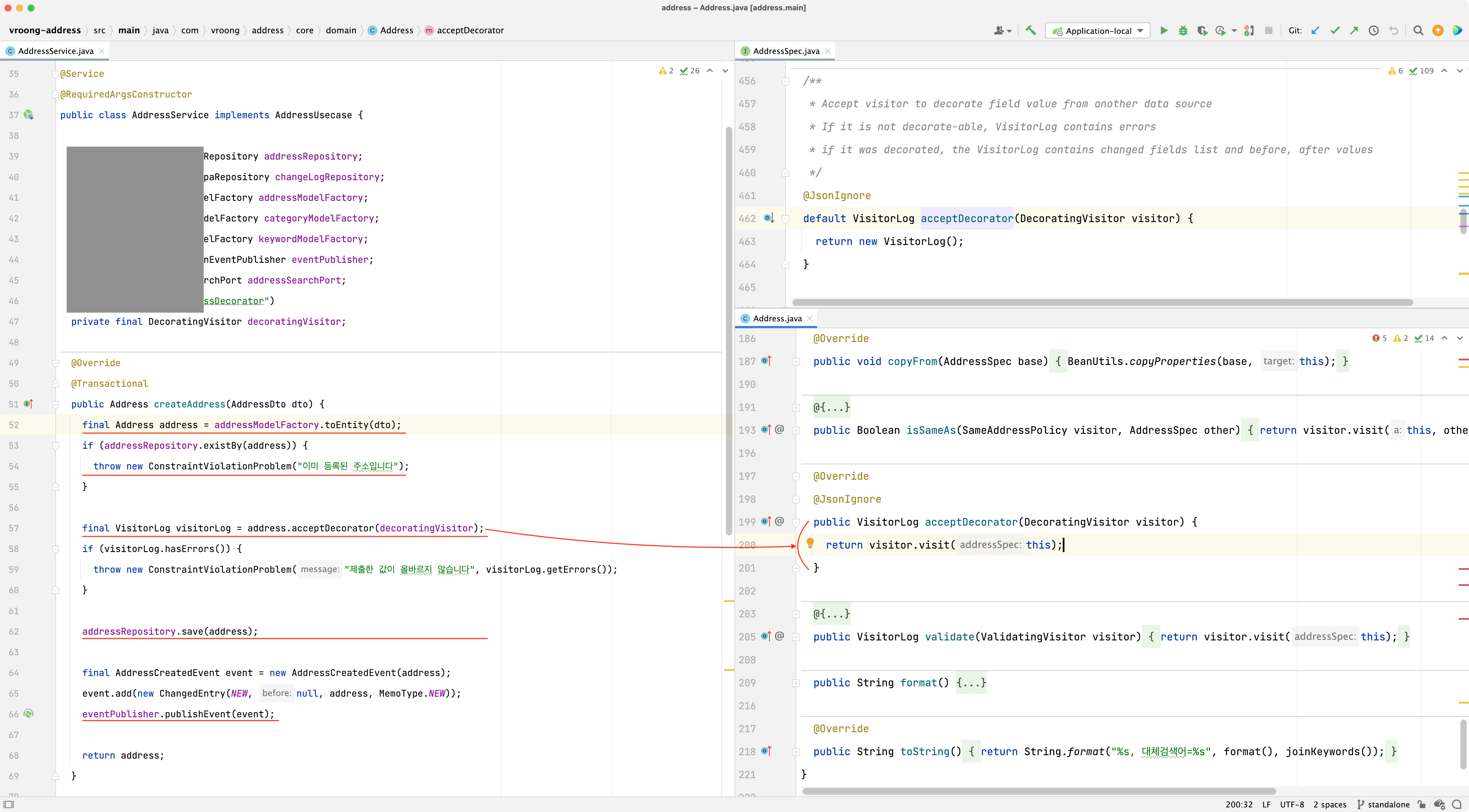
위에서 봤던 그림이랑 다른 주소 서비스입니다. 왼쪽이 Service, 오른쪽이 AggregateRoot Entity(이하 “모델”이란 용어와 혼용합니다) 입니다. 새 주소를 등록하는 유스케이스입니다. Service는 다음과 같은 일을 합니다.
- 50줄: 데이터베이스 트랜잭션을 관리합니다;
@Transactional애너테이션을 애플리케이션 안에서 사용하는 부분에 대한 의견이 갈릴 수 있습니다. 다시 한번 강조하지만 저는 실용주의자입니다, 갑자기 Quarkus 프레임웍으로 갈아탈 가능성은 없다고 봅니다 - 52줄: 클라이언트가 제출한 DTO로부터 도메인 모델을 만듭니다
- 54줄: 이미 등록된 주소인지 유효성 검사를 합니다
- 57줄:
DecoratingVisitor객체를 도메인 모델에게 전달하고, 전달받은DecoratingVisitor를 구동하여 모델 자신의 상태를 변경하라고 모델에게 메시지를 전달합니다;DecoratingVisitor는 현재 모델의 데이터 중, 꼭 필요하지만 비어있는 필드의 값을 주소 정제 엔진을 통해 구해와서 채워줍니다 - 59줄: 데코레이팅하는 과정에서 주소 정제 엔진이 현재 모델이 가진 주소를 정제할 수 없는 경우에 에러 목록을 반환하고, 에러가 한 건이라도 있으면 예외를 던집니다; 도메인 모델의 상태에 대한 일종의 불변식이라 할 수 있습니다
- 62줄: 도메인 모델의 상태를 영속화합니다
- 66줄: 어떤 필드가 어떤 값before에서 어떤 값after으로 변경되었는지를 애플리케이션 이벤트에 담아 변경 로그를 기록합니다
응용 서비스가 복잡하다면 응용 서비스에서 도메인 로직을 구현하고 있을 가능성이 높다. 응용 서비스가 도메인 로직을 일부 구현하면 코드 중복, 로직 분산 등 코드 품질에 안 좋은 영향을 줄 수 있다. 응용 서비스는 트랜잭션 처리도 담당한다. 응용 서비스는 도메인의 상태 변경을 트랜잭션으로 처리해야 한다. (후략) 🔗
위에서 언급한 응용 서비스에 도메인 로직을 구현하는 스타일을 트랜잭션 스트립트 패턴 이라 합니다 Patterns of Enterprise Application Architecture (2003, Martin Fowler). 트랜잭션 스크립트 스타일이 구시대적이고 잘못됐다고 말하는 것은 아니니 오해없으시길 바랍니다.
다만 도메인 모델에 도메인의 지식을 캡슐화하는 방식과 대별되는 방식 중 하나입니다. 트랜잭션 스크립트 스타일로 애플리케이션을 작성하면 도메인 모델은 표현력이 빈약해집니다 Anemic domain model . 도메인 모델이 데이터만 있고 로직은 없어서 DB의 컬럼을 수직으로 세워놓은 클래스가 될 가능성이 큽니다. 더군다나, 서비스에서 모델의 데이터 구조를 꺼내서 조작하고 다시 넣는 행위를 해야하므로 Tell Don’t Ask, Law Of Demeter 설계 원칙을 위반하게 됩니다.
Test
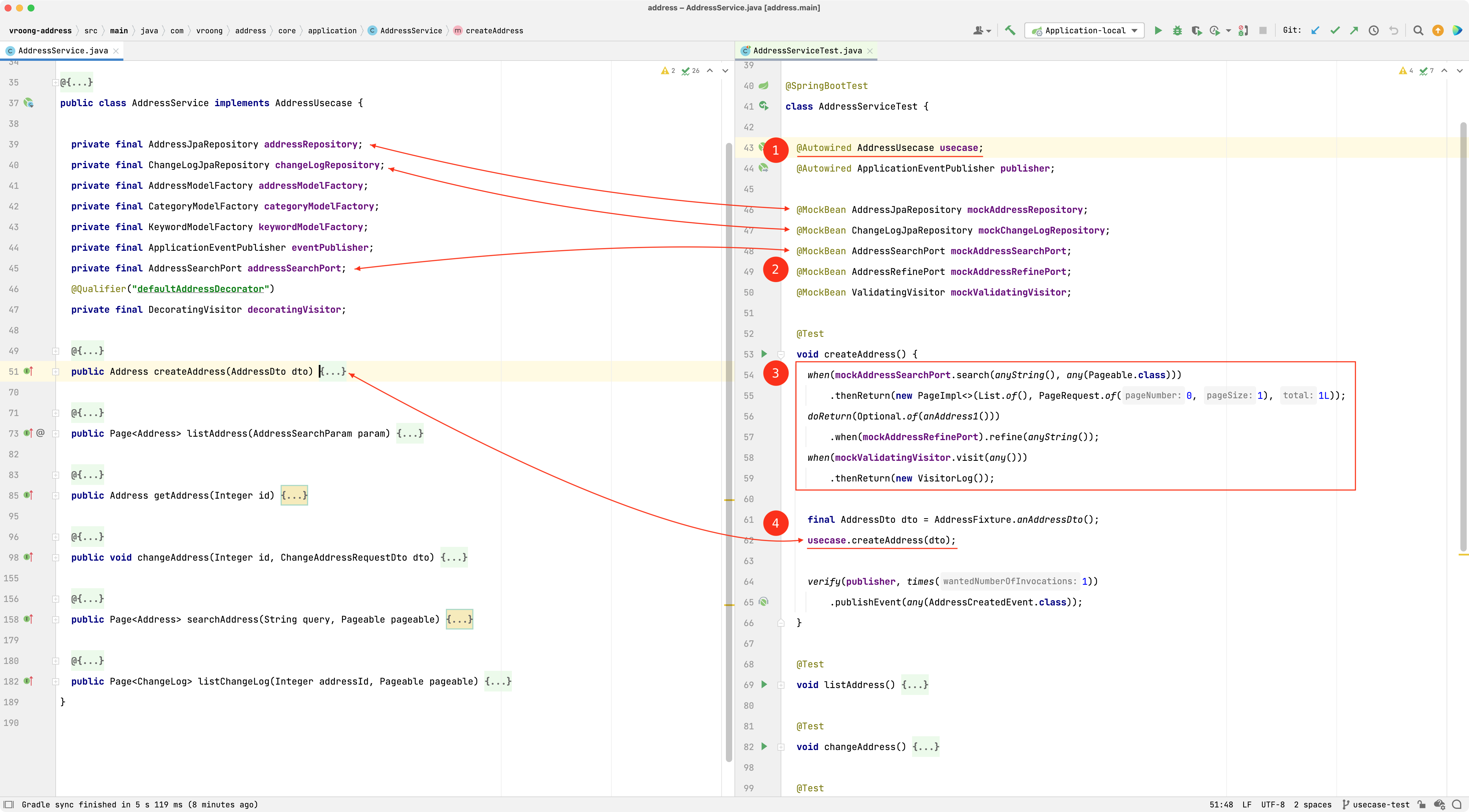
- ①
AddressUsecase가 테스트 대상입니다 - ② 테스트 대상이 의존하는 객체중 모의 객체로 대체할 대상입니다
- ③ 모의 객체의 동작을 정의합니다
- ④ 테스트하려는 메서드를 호출합니다
@SpringBootTest, @MockBean을 쓰지 않고도 테스트를 작성할 수 있습니다만… 그러기 위해서는 JpaRepository를 한번 더 감싼 클래스로 기존 구현을 전부 변경해야 하고, 테스트 컨텍스트에 ~Port, ~Factory, ~Visitor를 @Bean으로 등록하고 테스트 대상 클래스를 new up 해야 했을 겁니다. 이 지점에서도 역시 실용주의를 선택했습니다.
Closing Remarks
필자는 닭 잡는데 소잡는 칼을 쓰는 것을 매우 경계합니다. 한번 쓰고 버리는 애플리케이션을 만든다면, 또는 일회성으로 남의 서비스를 개발한다면, 빠르게 개발하는 방법을 택할겁니다. 그렇지만 내가 계속 유지보수해야할 서비스라면 소프트웨어의 제 2가치를 추구할겁니다.
소프트웨어의 제 1가치는 현재의 요구사항을 충족하는 것이고, 제 2가치는 미래의 요구사항을 충족하는 것입니다. 현재의 구현이 미래의 요구사항 변경을 반영하기 어려운 구조라면 좋은 소프트웨어라 할 수 없습니다. 가치있는 소프트웨어를 만드는 방법은 여러 가지인데, Hexagonal과 DDD도 괜찮은 선택지라 생각합니다.
Reference
참고하면 좋은 내용들입니다. 포스트 중간에 링크로 담은 내용은 제외했습니다.