데이터베이스 쿼리 성능 차이를 이해하기 위한 실험 share
많은 양의 데이터를 체계적으로 저장하기 위해 데이터베이스를 사용합니다. 필요할 때마다 빠르게 꺼내 보거나, 수정하고, 불필요해지면 삭제하기도 합니다. 이처럼 데이터베이스는 수 많은 레코드셋에서 원하는 레코드만 빠르게 추출해 낼 수 있는데, 내부에서 어떻게 작동하는 지는 완전 블랙박스죠?
가령 ‘인덱스를 걸면 빠르다’, ‘조인은 느리다’처럼 일반적으로 알려진 상식이 있고, 이런 상식에 따라 모델링을 하면 대체적으로 잘 돌아가지만…
최근 회사에서 관련된 일도 있었고 해서, 스물스물 호기심이 발동하기 시작했습니다.
MySQL은 소스코드가 깃허브에 완전 공개되어있어 블랙박스라 할 수는 없지만, 죽을 때까지 코드를 까볼 생각은 없습니다. 대신 간단한 배열을 이용해서 데이터베이스를 흉내내고, 기본 키(Primary Key), 문자열 컬럼에 대한 풀 스캔, 바이너리 스캔, 인덱스, 조인 등에서 성능 차이가 발생하는 이유를 추측해보기로 했습니다.
이 실험을 위한 소스코드는 이곳에서 다운로드 받을 수 있습니다.
1. 실험 도구
웹 브라우저를 이용해서 각 실험 시나리오를 수행하고 화면에 결과를 출력하는 간단한 실험 도구를 만들어 봤습니다.
다음과 같은 폴더로 구성했습니다.
.
├── app # 모델(PHP Class)입니다.
│ │ # PSR4 오토로드를 이용합니다.
│ ├── Model.php
│ ├── Team.php
│ └── User.php
├── data # 실험에 사용할 데이터를 생성합니다 (모델 인스턴스들로 구성된 배열).
│ │ # 테스트 러너에서 파일을 임포트합니다.
│ ├── index.php
│ ├── teams.php
│ └── users.php
├── scenario # 테스트 시나리오입니다.
│ │ # 테스트 러너에서 파일을 임포트합니다.
│ ├── binary.php
│ ├── fullscan.php
│ ├── indexed.php
│ ├── join.php
│ └── primary.php
└── index.php # 테스트 러너입니다.
테스트 러너(index.php)는
- 필요한 데이터를 생성하여 메모리에 로드하고
- 테스터와 인터랙션하기 위한 간단한 라우팅과
- 사용자가 선택한 시나리오를 수행한 후
- 결과를 계산하고 출력하는
총 네 개의 모듈로 구성되어 있습니다.
<?php // index.php
// 오토로드
require(__DIR__ . '/vendor/autoload.php');
// 허용 메모리 키우고, 테스트 데이터 생성
ini_set('memory_limit', '512M');
$teams = require(__DIR__ . '/data/teams.php');
$users = require(__DIR__ . '/data/users.php');
$userIndex = require(__DIR__ . '/data/index.php');
// 타이머 시작
define('START', microtime(true));
// 변수 초기화
$uri = $_SERVER['REQUEST_URI'] ?? null;
$scenario = trim(parse_url($uri)['path'], '/');
$allowed = [
'primary',
'fullscan',
'binary',
'indexed',
'join',
];
// 유효성 검사
if (in_array($scenario, $allowed, true) === false) {
throw new Exception('정의되지 않은 시나리오입니다.');
}
// 테스트 수행
$found = require(__DIR__ . "/scenario/{$scenario}.php");
// 결과 계산
$result = [
'처리시간(ms)' => (microtime(true) - START) * 1000,
'메모리(MB)' => memory_get_usage() / 1000000,
'CPU(%)' => sys_getloadavg()[0],
'found' => $found,
];
// 결과 출력
header('Content-Type: application/json;charset=utf-8');
echo json_encode($result, JSON_PRETTY_PRINT);
2. 실험 데이터 생성
App\Team , App\User 모델은 POPO(Plain Old PHP Object)이라 설명을 생략했으니, 소스코드를 살펴보시기 바랍니다.
2.1. $teams 배열
인덱스나 조인할 때 사용할 데이터입니다. 총 네 개를 만들었습니다.
<?php // data/teams.php
use App\Team;
return [
new Team([
'id' => 1,
'name' => '청팀',
'since' => 1970,
'subscription' => 'monthly'
]),
new Team([...]),
new Team([...]),
new Team([
'id' => 4,
'name' => '흑팀',
'since' => 2000,
'subscription' => 'forever'
]),
];
2.2. $users 배열
User 인스턴스 만 개를 담은 배열입니다. Faker 라이브러리와 같이 동작해서 매번 테스트 시나리오를 수행할 때마다 지난 번과 다른 일 만 개의 User 인스턴스를 담은 배열을 새로 만듭니다. 각 인스턴스는 Team 모델에 team_id라는 속성으로 연결되어 있습니다.
<?php // data/users.php
use App\User;
$faker = \Faker\Factory::create('ko_KR');
$users = [];
foreach (range(1, 10000) as $id) {
$team = $faker->randomElement($teams);
$users[] = new User([
'id' => $id,
'name' => "{$faker->name}_{$id}",
'email' => $faker->safeEmail,
'team_id' => $team->id
]);
}
return $users;
2.3. $userIndex 배열
필자는 인덱스를 일종의 그룹핑이라고 생각했습니다. 가령 만 개의 User 인스턴스로 구성된 레코드셋을 총 네 개의 Team으로 구분할 수 있다면, 풀스캔의 대상은 1/4로 줄어들기 때문입니다. 정식으로 공부해 본 적이 없는 데알못인데, 개발자의 촉으로 users.team_id 컬럼에 인덱스를 건다면, 1:(1,2,..), 2:(3,7,..), team_id:(users.id 리스트) 식으로 어딘가에 저장해 놓고, 쿼리 시점에 저장된 맵(인덱스)를 먼저 탐색하지 않을까 싶습니다.
<?php // data/index.php
$userIndex = [];
foreach ($users as $user) {
$userIndex[$user->team_id][] = $user;
}
return $userIndex;
참고 이 코드에서 foreach를 사용하는 것이 array_map을 사용하는 것 보다 더 빨랐습니다.
3. 시나리오
1 절의 테스트 러너에서 봤듯이 데이터 생성이 끝난 후 타이머를 시작하고, 테스터가 선택한 시나리오를 수행합니다.
이하 모든 실험 환경은 필자의 맥북 프로기준이며, PHP 7.1(xdebug on, opcache off)과 라라벨 Valet 서버를 이용했습니다.
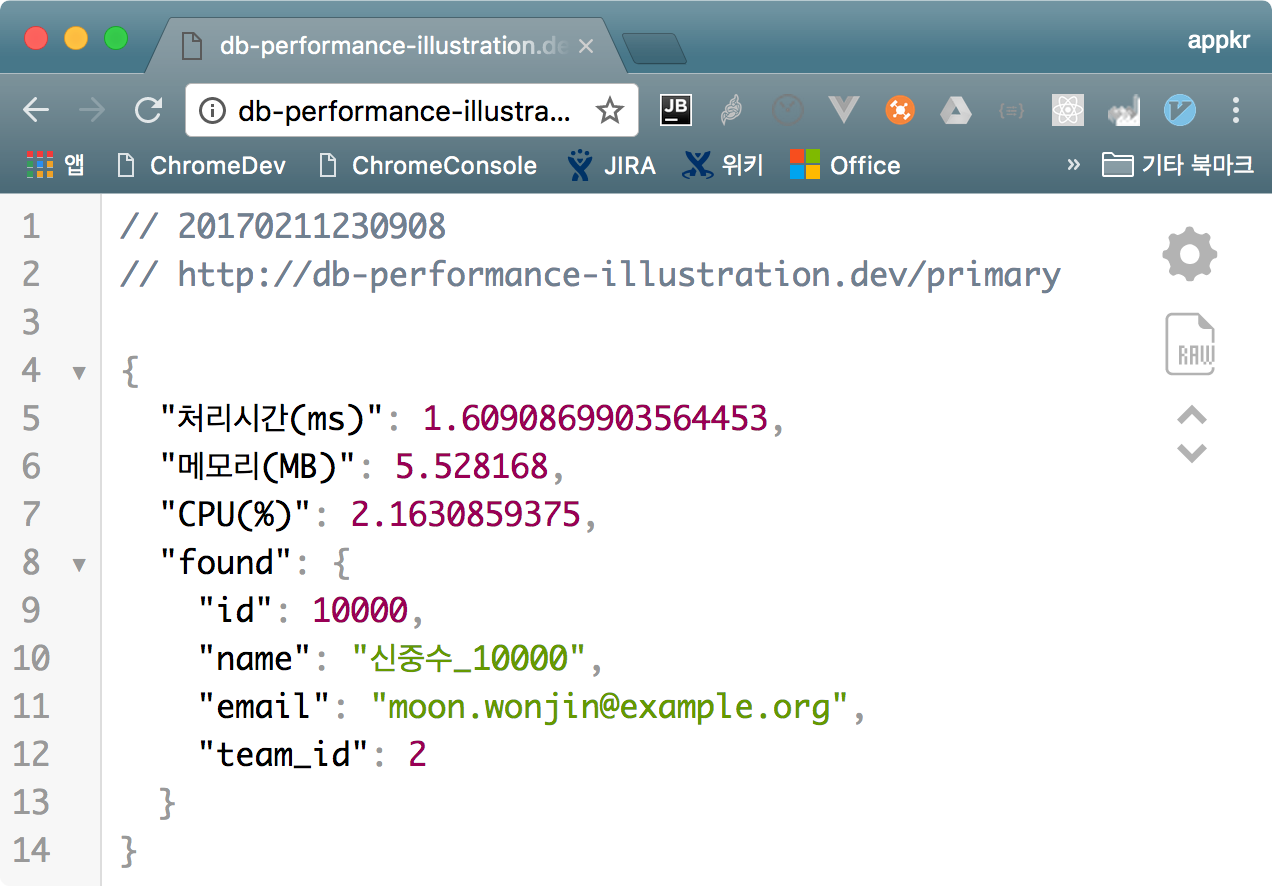
3.1. primary 시나리오
데이터베이스의 기본 키 쿼리를 흉내냅니다. 필자는 배열의 인덱스를 바로 접근하는 것과 비슷하다고 생각하고 다음과 같이 시나리오 코드를 구성했습니다.
<?php // scenario/primary.php
return $users[9999];
총 5회 실험하고, 처리시간 기준으로 아웃라이어 2개는 버렸습니다.
GET /primary
| 구분 | 처리시간(ms) | 메모리(MB) | CPU(%) |
|---|---|---|---|
| 1 | 1.645088196 | 5.5276 | 1.685058594 |
| 2 | 1.547813416 | 5.528152 | 1.797851563 |
| 3 | 1.681804657 | 5.527568 | 1.865722656 |
| 평균 | 1.624902089 | 5.527773333 | 1.782877604 |
3.2. fullscan 시나리오
문자열 컬럼을 풀스캔하는 쿼리를 흉내냅니다.
<?php // scenario/fullscan.php
foreach ($users as $user) {
if (strpos($user->name, '_9999') !== false) {
return $user;
}
}
return new \App\User;
총 5회 실험하고, 처리시간 기준으로 아웃라이어 2개는 버렸습니다.
GET /fullscan
| 구분 | 처리시간(ms) | 메모리(MB) | CPU(%) |
|---|---|---|---|
| 1 | 9.595155716 | 5.528248 | 2.473632813 |
| 2 | 9.42492485 | 5.527952 | 2.122070313 |
| 3 | 12.29596138 | 5.527776 | 2.5234375 |
| 평균 | 10.43868065 | 5.527992 | 2.373046875 |
3.3. indexed 시나리오
인덱스된 컬럼을 쿼리하는 시나리오입니다. ‘흑팀’에서 사용자 이름이 _9999로 끝나는 레코드를 찾는데, 앞서 말했듯이 매번 만 개의 테스트 데이터를 생성하기 때문에, _9999 사용자가 ‘흑팀’이 아닐 수도 있어서, 빈 레코드를 반환할 수도 있습니다. 빈 레코드가 반환될 때는 ‘흑팀’에 해당하는 대략 2500개의 레코드를 끝까지 스캔하기 때문에 미미하지만 시간이 더 오래 걸릴 수 있습니다.
<?php // scenario/indexed.php
foreach ($userIndex[4] as $user) {
if (strpos($user->name, '_9999') !== false) {
return $user;
}
}
return new \App\User;
총 5회 실험하고, 처리시간 기준으로 아웃라이어 2개는 버렸습니다.
GET /indexed.php
| 구분 | 처리시간(ms) | 메모리(MB) | CPU(%) |
|---|---|---|---|
| 1 | 3.381967545 | 5.5282 | 1.997558594 |
| 2 | 4.05216217 | 5.528056 | 1.793457031 |
| 3 | 3.484964371 | 5.52896 | 1.578613281 |
| 평균 | 3.639698029 | 5.528405333 | 1.789876302 |
3.4. join 시나리오
users 테이블과 teams 테이블간의 조인 쿼리를 흉내냅니다. 휙 봐도 반복문이 두 번 등장하고, $joined라는 만 개의 원소를 담고 있는 새로운 배열이 메모리 공간에 생기게 되므로, 당연히 테이블 한 개보다 처리에 오랜 시간이 걸릴 수 밖에 없을 겁니다.
게다가 우리 시나리오의 경우, 찾고자 하는 값이 배열 맨 끝에 위치하고 있어 총 2 만번의 루프가 발생하고 있습니다.
@huhushow님의 가르침으로 검색을 먼저하고 맵핑하는 로직으로 변경했습니다. 배열 순회 회수는 풀스캔과 같고, 찾은 사용자가 속한 Team을 찾아 머지하는 로직만 추가 되었으므로 풀스캔 대비 성능 차이는 거의 없었습니다.
<?php // scenario/join.php
$found = null;
foreach ($users as $user) {
if (strpos($user->name, '_9999') !== false) {
$found = $user;
}
}
if ($found) {
$team = $teams[$found->team_id - 1];
$found->team_name = $team->name;
$found->team_since = $team->since;
$found->team_subscription = $team->subscription;
return $found;
}
return new \App\User;
총 5회 실험하고, 처리시간 기준으로 아웃라이어 2개는 버렸습니다.
GET /join.php
| 구분 | 처리시간(ms) | 메모리(MB) | CPU(%) |
|---|---|---|---|
| 1 | 10.13612747 | 5.528432 | 2.827148438 |
| 2 | 10.37597656 | 5.529192 | 1.83203125 |
| 3 | 10.39290428 | 5.528472 | 2.174804688 |
| 평균 | 10.30166944 | 5.528698667 | 2.277994792 |
3.5. binary 시나리오
실험 목적과는 좀 거리가 있지만, 좀 더 지능적인 풀스캔 전략을 보여주기 위해 수록했습니다. 바이너리 검색에 대한 자세한 내용은 Algorithm Visualizer 프로젝트를 참고해주세요.
<?php // scenario/binary.php
$search = 9999;
$startIndex = 0;
$endIndex = count($users) - 1;
while ($endIndex > $startIndex) {
$medianIndex = ($startIndex + $endIndex);
if ($search > $users[$medianIndex]->id) {
$startIndex = $medianIndex + 1;
} elseif ($search < $users[$medianIndex]->id) {
$endIndex = $medianIndex - 1;
} else {
return $users[$medianIndex];
}
}
return new \App\User;
총 5회 실험하고, 처리시간 기준으로 아웃라이어 2개는 버렸습니다.
GET /binary.php
| 구분 | 처리시간(ms) | 메모리(MB) | CPU(%) |
|---|---|---|---|
| 1 | 7.062911987 | 5.528104 | 2.474121094 |
| 2 | 2.383947372 | 5.52812 | 2.753417969 |
| 3 | 1.770973206 | 5.528288 | 3.248535156 |
| 평균 | 3.739277522 | 5.528170667 | 2.825358073 |
4. 관찰 결과 및 시사점
막연하게만 알던 내용을, 실험을 통해 검증하는 계기가 되었습니다. @huhushow님의 의견의 따라 로직을 수정하니 결론은 완전히 달라졌습니다.
- 어떤 방식을 사용하든 풀스캔의 대상이 될 레코드셋의 양을 줄이는 것은 성능 향상에 도움이 된다.
테이블 조인은 메모리를 많이 사용하고, 속도도 느리다.
데이터베이스 모델링할 때, 중복을 최소화하고, 데이터간 무결성을 유지하기 위해 정규화를 했습니다. 하지만 레코드 수가 많아지면 조인으로 인한 성능 낭비가 커지므로, 조인이 잦은 테이블을 비정규화하여 약간의 중복을 허용하는 식으로 구성하는 것도 좋은 방법이란 생각이 들었습니다. 또는 조인할 때 참조되는 테이블을 애플리케이션의 배열이나 인-메모리 캐시에 올려두는 것도 생각해 볼 수 있겠네요.
5. MySQL 테스트
이상의 테스트를 MySQL에서 그대로 재연하고 결과를 측정해 보았습니다.
맥용 Docker에 mysql:5.7 이미지를 이용했고, SequelPro를 클라이언트로 사용했습니다.
테스트에 사용한 쿼리는 아래와 같습니다. 테이블 스키마를 생성하고 데이터를 심는 쿼리는 소스코드의 /sql 폴더에서 찾을 수 있습니다. 역시 만 개의 users 레코드와 네 개의 teams 레코드를 만들었습니다. 애플리케이션이 아니므로 매 시나리오를 수행할 때마다 테스트 벡터가 달라지지는 않습니다.
-- #1 primary
SELECT *
FROM `users`
WHERE `id` = 99999;
-- #2 fullscan
SELECT *
FROM `users`
WHERE `name` LIKE '%_99999';
-- #3 indexed
SELECT *
FROM `users`
WHERE `team_id` = 4;
-- #4 join
SELECT *
FROM `users` as u, `teams` as t
WHERE u.`team_id` = t.`id`
AND t.`name` = '홍팀'
AND u.`name` LIKE '%_99997';
동일하게 5회 실험하고, 처리시간 기준으로 아웃라이어 2개는 버렸습니다.
| SQL | 시나리오 | 3회 평균 처리 시간(ms) |
|---|---|---|
| #1 | primary |
2.233333333 |
| #2 | fullscan |
46.06666667 |
| #3 | indexed |
13.36666667 |
| #4 | join |
35.16666667 |
스택오버플로에 올라온 ‘mysql 5.0 indexes - Unique vs Non Unique’라는 질답의 좌표를 남기며 마칩니다. 링크의 내용을 요약하면 성능은 Primary > Unique > Index > Non-indexed Primary > Unique & Non-Unique-Index > Non-indexed 순이란 이야기입니다.